CVPR 2025
Exemples
- Facial analysis (Büchner et al. 2025)
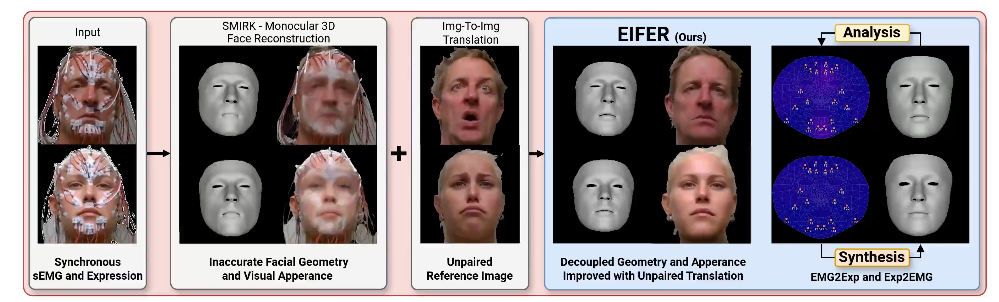
Exemples
- Facial analysis (Büchner et al. 2025)
- 3D hair reconstruction (Rosu et al. 2025)

Exemples
- Facial analysis (Büchner et al. 2025)
- 3D hair reconstruction (Rosu et al. 2025)
- 2D -> 3D point cloud (best paper) (Wang et al. 2025)
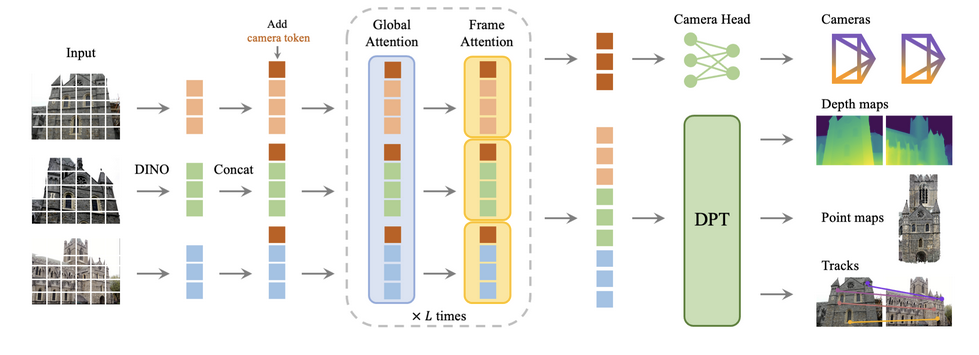
Exemples
- Facial analysis (Büchner et al. 2025)
- 3D hair reconstruction (Rosu et al. 2025)
- 2D -> 3D point cloud (best paper) (Wang et al. 2025)
- 2D -> 3D object primitives (Zhao et al. 2025)
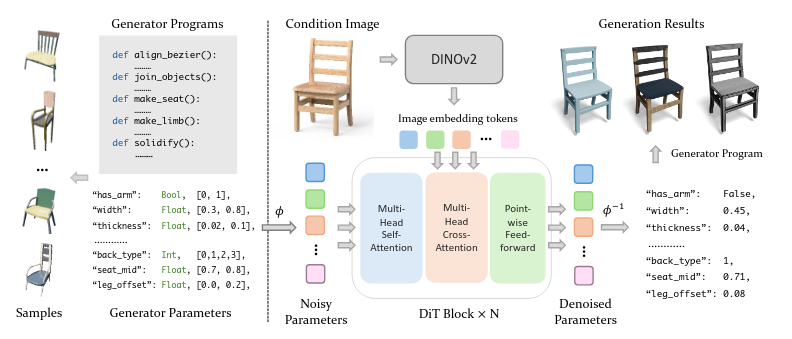
Exemples
- Facial analysis (Büchner et al. 2025)
- 3D hair reconstruction (Rosu et al. 2025)
- 2D -> 3D point cloud (best paper) (Wang et al. 2025)
- 2D -> 3D object primitives (Zhao et al. 2025)
- Removing reflections from images (Kee et al. 2025)

Exemples
- Facial analysis (Büchner et al. 2025)
- 3D hair reconstruction (Rosu et al. 2025)
- 2D -> 3D point cloud (best paper) (Wang et al. 2025)
- 2D -> 3D object primitives (Zhao et al. 2025)
- Removing reflections from images (Kee et al. 2025)
And probably much more!
Büchner, Tim, Christoph Anders, Orlando Guntinas-Lichius, and Joachim Denzler. 2025. “Electromyography-Informed Facial Expression Reconstruction for Physiological-Based Synthesis and Analysis.” In Proceedings of the Computer Vision and Pattern Recognition Conference, 215–27.
Kee, Eric, Adam Pikielny, Kevin Blackburn-Matzen, and Marc Levoy. 2025. “Removing Reflections from Raw Photos.” In Proceedings of the Computer Vision and Pattern Recognition Conference, 161–71.
Rosu, Radu Alexandru, Keyu Wu, Yao Feng, Youyi Zheng, and Michael J Black. 2025. “DiffLocks: Generating 3D Hair from a Single Image Using Diffusion Models.” In Proceedings of the Computer Vision and Pattern Recognition Conference, 10847–57.
Wang, Jianyuan, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. 2025. “Vggt: Visual Geometry Grounded Transformer.” In Proceedings of the Computer Vision and Pattern Recognition Conference, 5294–5306.
Zhao, Wang, Yan-Pei Cao, Jiale Xu, Yuejiang Dong, and Ying Shan. 2025. “Di-Pcg: Diffusion-Based Efficient Inverse Procedural Content Generation for High-Quality 3d Asset Creation.” In Proceedings of the Computer Vision and Pattern Recognition Conference, 11061–72.