Non rigid diffusion:
Application to shape matching
Objective: data-driven shape matching
Final objective: shape matching
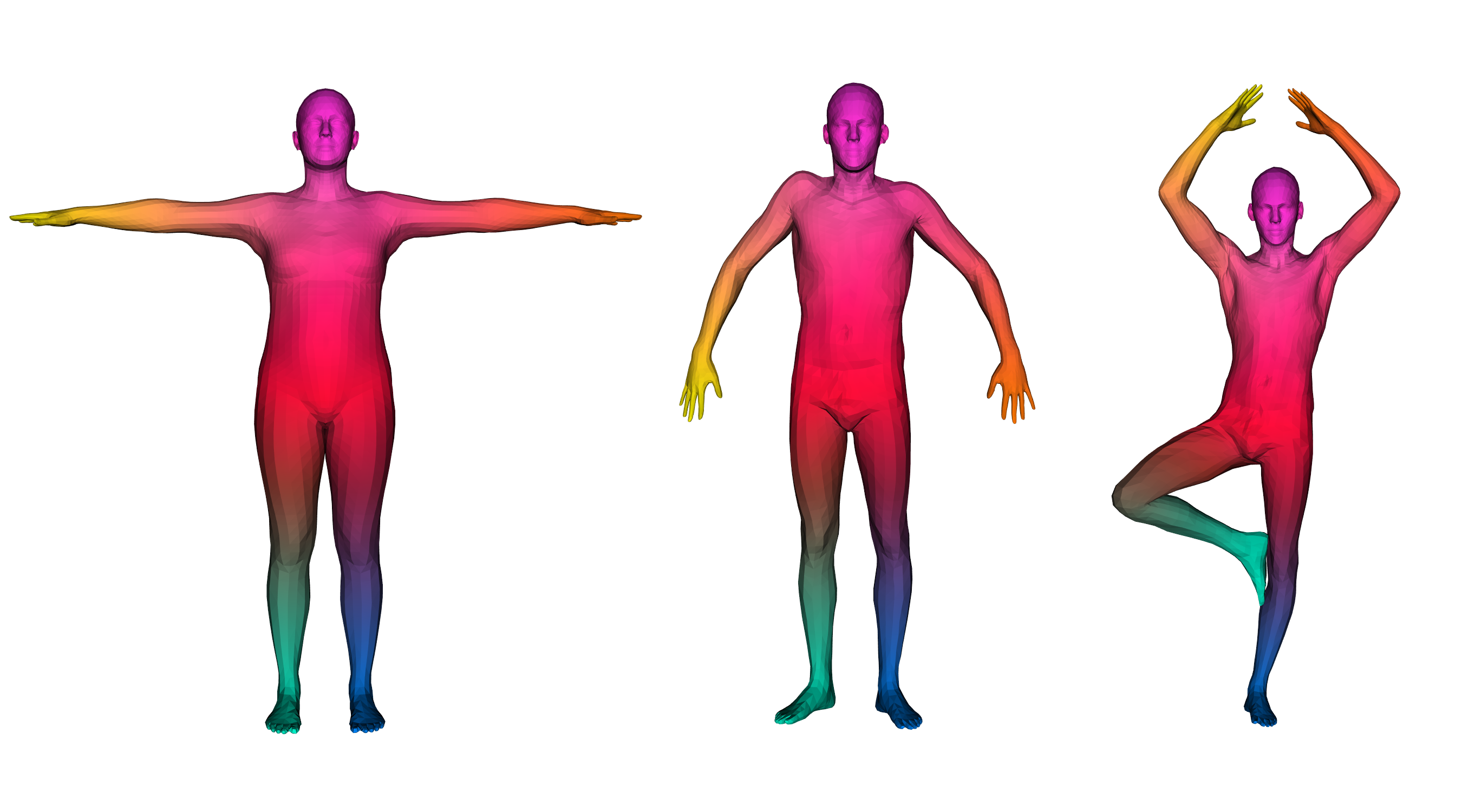
We have access to huge datasets of non rigid shapes nowadays.

The objective is to take profit of some huge databases of non rigid shapes to improve shape matching algorithms.
Shape matching algorithms are not perfect
A general problem in non rigid shape matching is dealing with symmetries. Regularizing algorithms with axiomatic constraints are not sufficient to get rid of this problem.
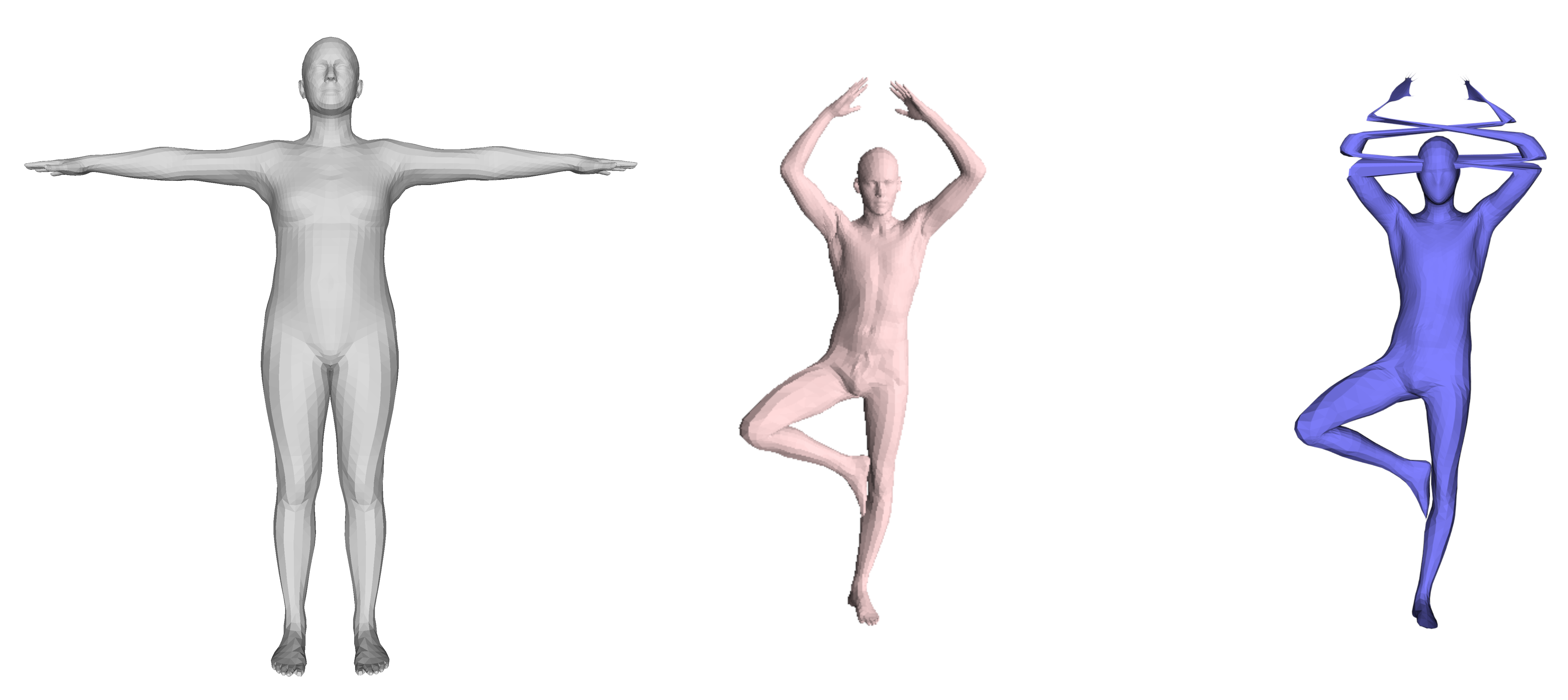
Is there a data-driven way to regularize the functional map and solve this problem ?
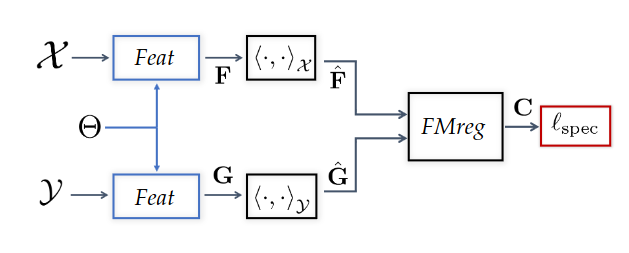
Background: Functional maps
Let’s have two shapes that we wan’t to match. The natural basis functions to choose are the Laplace Beltrami Operator (LBO) eigenfunctions. Now, suppose, we know a way to define a set of functions \(f_i\) on \(N\) and \(g_j\) on \(M\) such that \(g(x) \sim f \circ T^{-1} (x)\) (local descriptors which are isometry invariant).
We decompose all \(f_i\) as \(a \in \mathbb{R}^{n \times m}\) and \(g_j\) as \(b \in \mathbb{R}^{n \times m}\). The functional map can be defined as the solution of: \[ C = \underset{C}{\text{argmin}} ||Ca - b||² \]
In practice, we compute the pointwise descriptors using a neural network. Since the output of the previous equation can be obtained in closed form, we optimize the output \(C\) with respect to the ground truth map \(C_{gt}\) or with axiomatic constraints, allowing to learn the descriptors
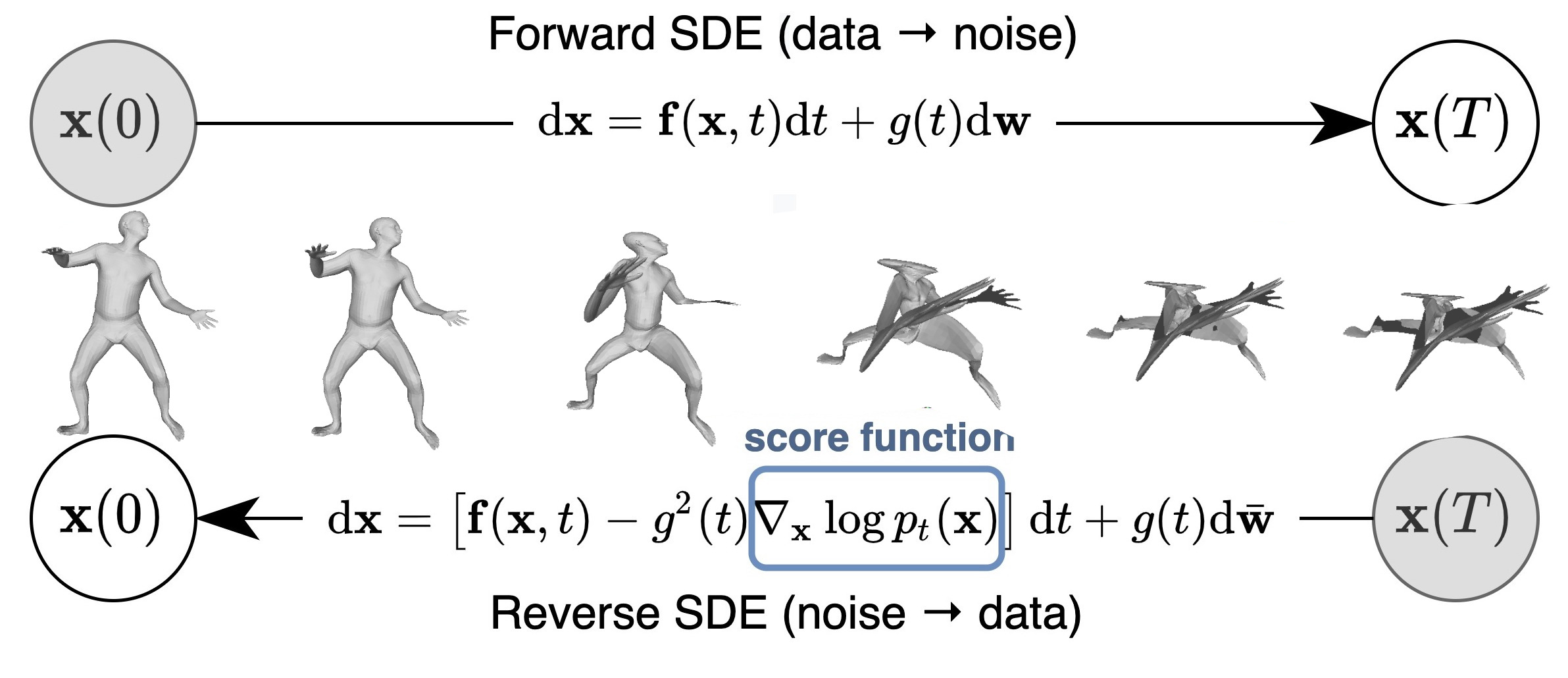
Promising path: denoising diffusion models
Denoising diffusion probabilistic models is currently the best way to learn a data distribution.
Starting point: learn a diffusion model on a set of already aligned non rigid shapes
Shape representation as PCA coefficients
Advantages:
- low dimensional (\(\sim 100\) coefficients vs. \(>15000\) points on human shapes)
- fast and “exact” recovery of PCA coefficients from shape/shape from PCA coefficients
- Recovery from Laplacian basis projection
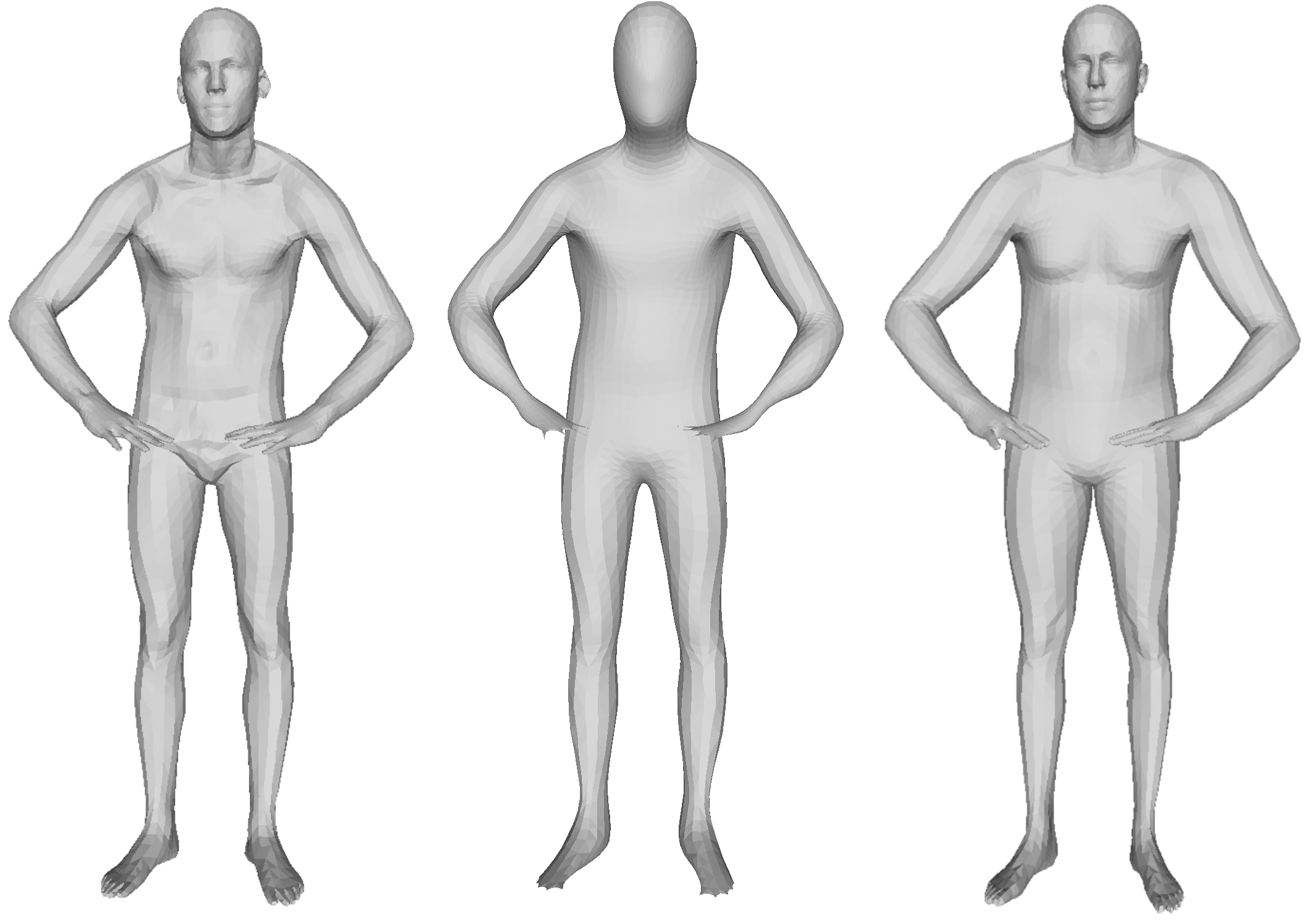
We learn a diffusion model on the set of PCA coefficients