Denoising diffusion using Stochastic Differential Equations
Evolution of the score modeling approach
Initial proposal: score matching(Hyvärinen and Dayan 2005)
The quantity \(Trace\left(\nabla_x^2 \log p_\theta(x)\right)\) is difficult to compute
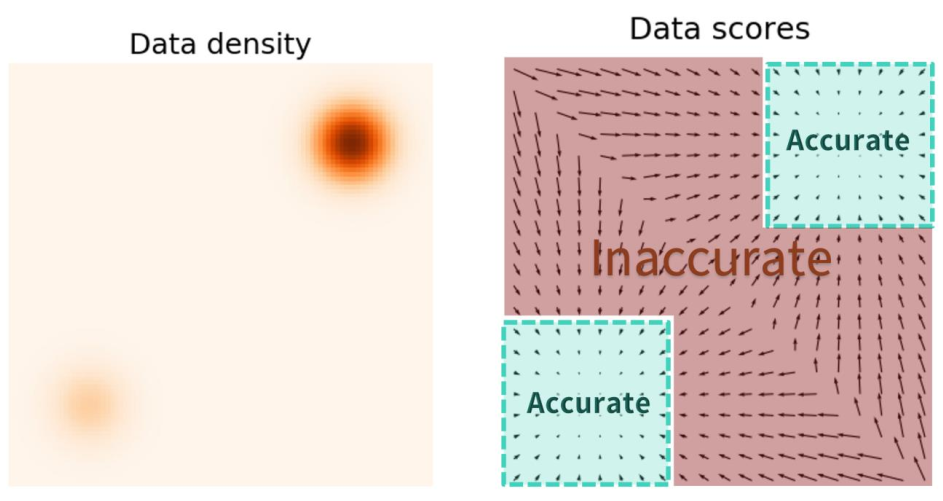
The score is untractable in low density areas
Given \(\{x_1, x_2, ..., x_T\} \sim p_\text{data}(x)\) Objective: Minimize the quantity \[ E_{p(x)}\left[\frac{1}{2}|| \log p_{\theta}(x)||² + Trace\left(\nabla_x^2 \log p_\theta(x)\right)\right]\]
Evolution of the score modeling approach
Initial proposal: score matching(Hyvärinen and Dayan 2005)
Learning the score of a noisy distribution(Vincent 2011)
No score of noise-free distribution
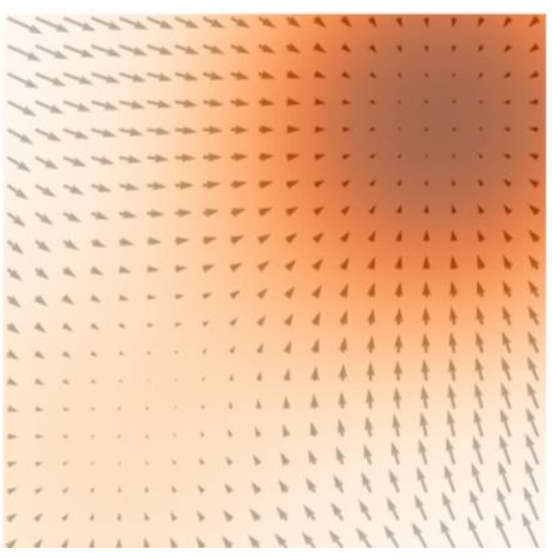
Loss: \(\mathbb{E}\left[\frac{1}{2}\left|\left| s_\theta(\tilde{x})- \frac{\tilde{x}-x}{\sigma²}\right|\right|²\right]\)
Evolution of the score modeling approach
Initial proposal: score matching(Hyvärinen and Dayan 2005)
Learning the score of a noisy distribution(Vincent 2011)
Denoising diffusion models(Sohl-Dickstein et al. 2015), annealed Langevin dynamics(Y. Song and Ermon 2019)
- Gradually decrease noise in the distribution
- Can obtain non noisy samples
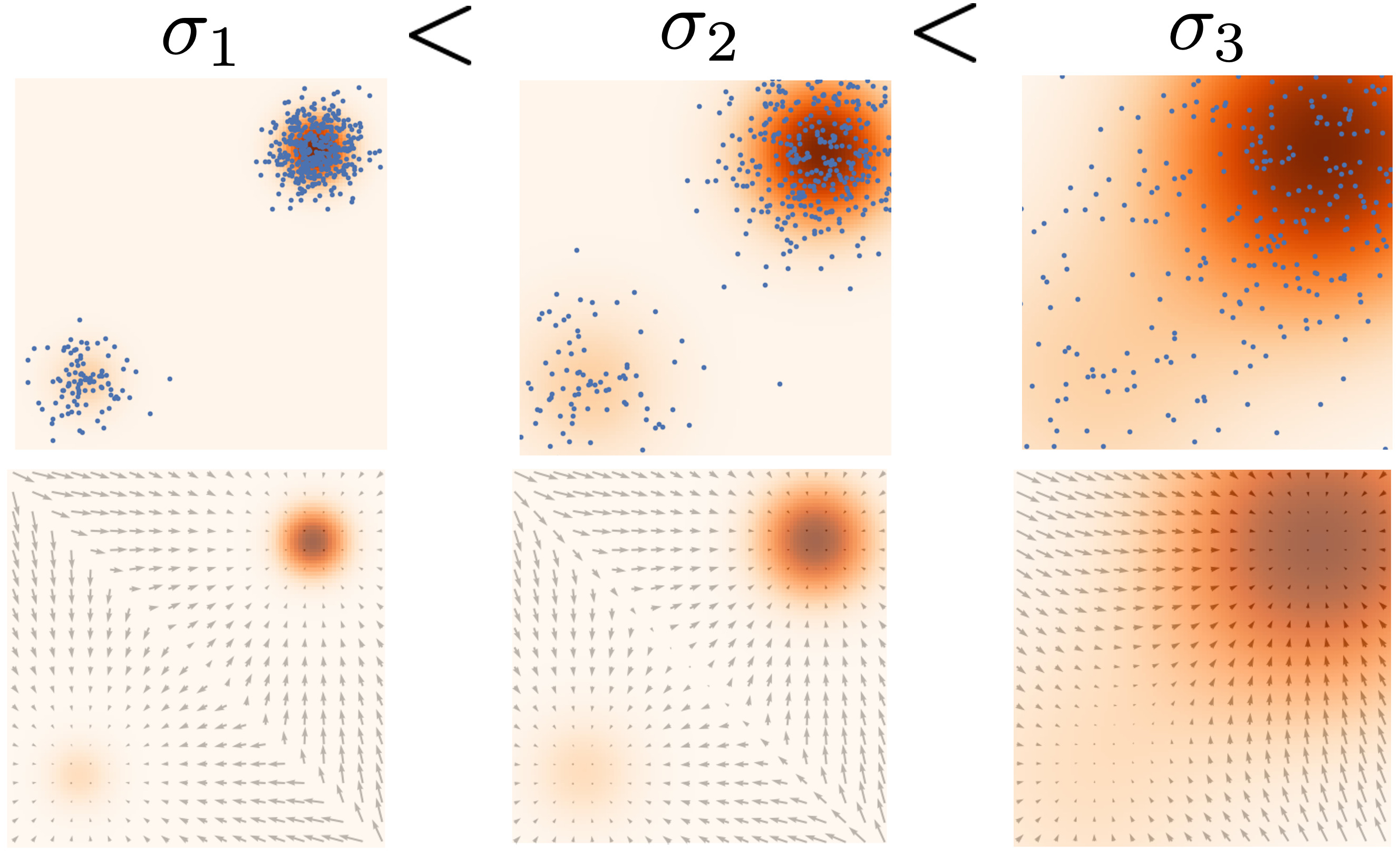
Noise conditional score model, with objective : \[ \frac{1}{L} \sum_{i=1}^L \lambda(\sigma_i) \mathbb{E}\left[\left\lvert\left\lvert s_\theta(x_i, \sigma_i) - \frac{(\tilde{x}_i - x_i)}{\sigma_i²}\right\rvert\right\rvert ² \right] \]
Evolution of the score modeling approach
Initial proposal: score matching(Hyvärinen and Dayan 2005)
Learning the score of a noisy distribution(Vincent 2011)
Denoising diffusion models(Sohl-Dickstein et al. 2015), annealed Langevin dynamics(Y. Song and Ermon 2019)
DDPM beats GAN(Ho, Jain, and Abbeel 2020)!

Algorithm
